Improved i/o in anndata 0.12
0.12 released
We’re happy to announce that anndata 0.12 is out now!
Check out the changelog for a full list of changes.
Here, we want to give our users a bit of a deep dive into the new functionality.
We have lots of great features, like zarr v3 support (package and format), full lazy loading, and new API customisability! Let’s dive in!
Zarr v3
Zarr v3 as a file format provides improved cloud support, support for sharding to reduce the number of files created in a zarr store, and improved support for extensibility. Check out the following graphic from the zarr docs: By grouping chunks into shards, which are the individual file units, we can cut down the number of files a given zarr store has. Compare this to zarr v2 where every chunk was its own file! No more file system slowdowns, you can create large zarr stores with no concerns while still retaining the ease of use of zarr.
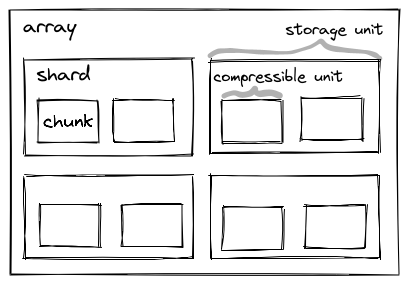
The zarr v3 package, on top of the new format, provides a fully concurrent + parallel backend for faster cloud and local access over v2, which was both single-threaded and synchronous. Thus, the new zarr v3 package on its own should provide a nice speedup, but if that’s not enough, various components are also extendable/replaceable.
Want faster cloud access? Try obstore integration for rust-accelerated remote file access What about faster local reads? Many very small chunks inside shards can be taxing for the current pure-python zarr v3 pipeline. Thus scverse core developers Philipp Angerer and Ilan Gold together with Lachlan Deakin at ANU co-developed the zarrs-python package for a python bridge to rust-based io acceleration from Lahclan’s zarrs package. This acceleration really shines with small, heavily sharded stores! Want to try out direct-to-gpu io? kvikio has a store for that, with a direct-to-GPU zstd codec is coming soon as well! And if all of these new functionalities are a lot to take in, we made a digestible guide just for you.
And of course, all of this new functionality has not broken our backwards compatibility. Anndata 0.12 is still fully zarr v2 compatible, both with the package and the file format. Upgrade fearlessly!
Fully lazy file access
Moving on, we have also replaced anndata.experimental.read_elem_as_dask with anndata.experimental.read_elem_lazy and anndata.experimental.read_lazy.
Why? Because now your dataframes can be lazy too thanks to support from xarray!
Now you can instantly and lazily inspect entire anndata stores both locally and remotely for metadata, and then fetch only subsets you need.
Mix this with zarr v3 for performant, fully lazy, fully remote (if needed) access! Want to create a new virtual in-memory anndata objects from many disparate on-disk stores? This new functionality is fully compatible with anndata.concat.
Check out our notebook to learn more about the API – thanks to Nils Gehlenborg’s HIDIVE lab for hosting the data, and be sure to check out the Vitessce visualisation of the very same data backing the notebook. This dual-access really showcases the power of smart remote data access!
Customizable API
And if that wasn’t enough, we now have a new way of extending the anndata API contributed by one of our community members, Sri Varra.
This contribution lets users extend the AnnData API easily, great for tinkering with new APIs and features but also for writing new methods directly into the AnnData object:
import anndata as ad
@ad.register_anndata_namespace("my_accessor")
class Greetings:
def __init__(self, adata: ad.AnnData):
self._adata = adata
def greet():
return "hi"
# and to use
adata.my_accessor.greet()
Especially as we look to a more extensible future with async access and a dataframe API, being able to write clean code that really fits your use-case is more important than ever. Thanks for the contribution! Please reach out on Github or Zulip if you wish to contribute to these efforts or others! We welcome community contributions and are happy to provide feedback and guidance!
— The scverse core team